Deriving the MSL/Apollo Entry Guidance Algorithm
NASA’s Mars Science Laboratory mission showcased an advancement in entry technology that allowed it to land much closer to its designated landing site than previous missions. It used with great success, the same guidance algorithm originally used by the Apollo Command Module when returning from the moon. By modulating its lift vector, MSL was able to counteract errors in its trajectory during hypersonic flight and combined with the famous “sky-crane” maneuver, deliver the Curiosity rover to within 2.5 km of its targeted landing site next to Gale Crater. Last year’s Mars 2020 mission used the same guidance system to successfully land the Perseverance rover within Jezero crater.
Apollo Guidance Algorithm Overview
The goal of the Apollo guidance algorithm is to minimize the error in “range” along the ground when compared to that of a pre-computed reference trajectory. It does not try to exactly match the reference trajectory, but instead computes a constant bank angle that is supposed to minimize the downrange distance error at the point where the vehicle reaches terminal altitude. This computation is repeated several times a second in the same manner as a closed-loop control system to correct for deviations in the trajectory due to external or internal factors.
The guidance algorithm uses bank angle to control the amount of vertical lift. This has the side-effect of causing lateral motion that takes the spacecraft away from the desired path. In order to account for this, the bank angle commanded is reversed when the predicted cross-range error exceeds a certain amount, effectively creating a series of S-turns. This is similar to the S-turns performed by the Space Shuttle during its re-entry.
This article focuses on the downrange error control.
2DOF Dynamic Model
The MSL entry vehicle is modeled in two-dimensions using a vehicle-centric polar coordinate system. The state variables in the model are altidude ($h$), downrange distance ($s$), speed ($v$) and flight path angle($\gamma$). Their equations of motion are as follows:
where
Surface atmospheric density, $\rho_0$ and scale height, $H$ define the exponential atmospheric model. $g$ is a constant value for acceleration due to gravity. $u$ is the bank angle of the vehicle. The states are collectively referred to as $\mathbf{x}$. The equations of motions may be collectively referred to as $\mathbf{f}(\mathbf{x}, u, t)$.
Deriving the Apollo Entry Guidance Algorithm
Note on the Variation Operator
This derivation requires the use of the “variation operator”, denoted by $\delta$, sometimes called a functional derivative or variational derivative. A functional is a function that acts on functions. For example, $J(y(t))$ is a functional because $y$ is itself a function of time. Here $J$ is a scalar quantity derived from a function $y(t)$, that essentially consists of an infinite number of points.
The variational operator is to functionals, what derivatives are to functions. Similar to how a stationary point of a function can be found by setting its derivative to zero, the stationary point of a functional can be found by setting its variation to zero.
Please check the following links if you want to learn more:
https://www.youtube.com/watch?v=vqDHO2eKXcs
https://canvas.vt.edu/files/1315932/download?download_frd=1
Deriving bank angle policy
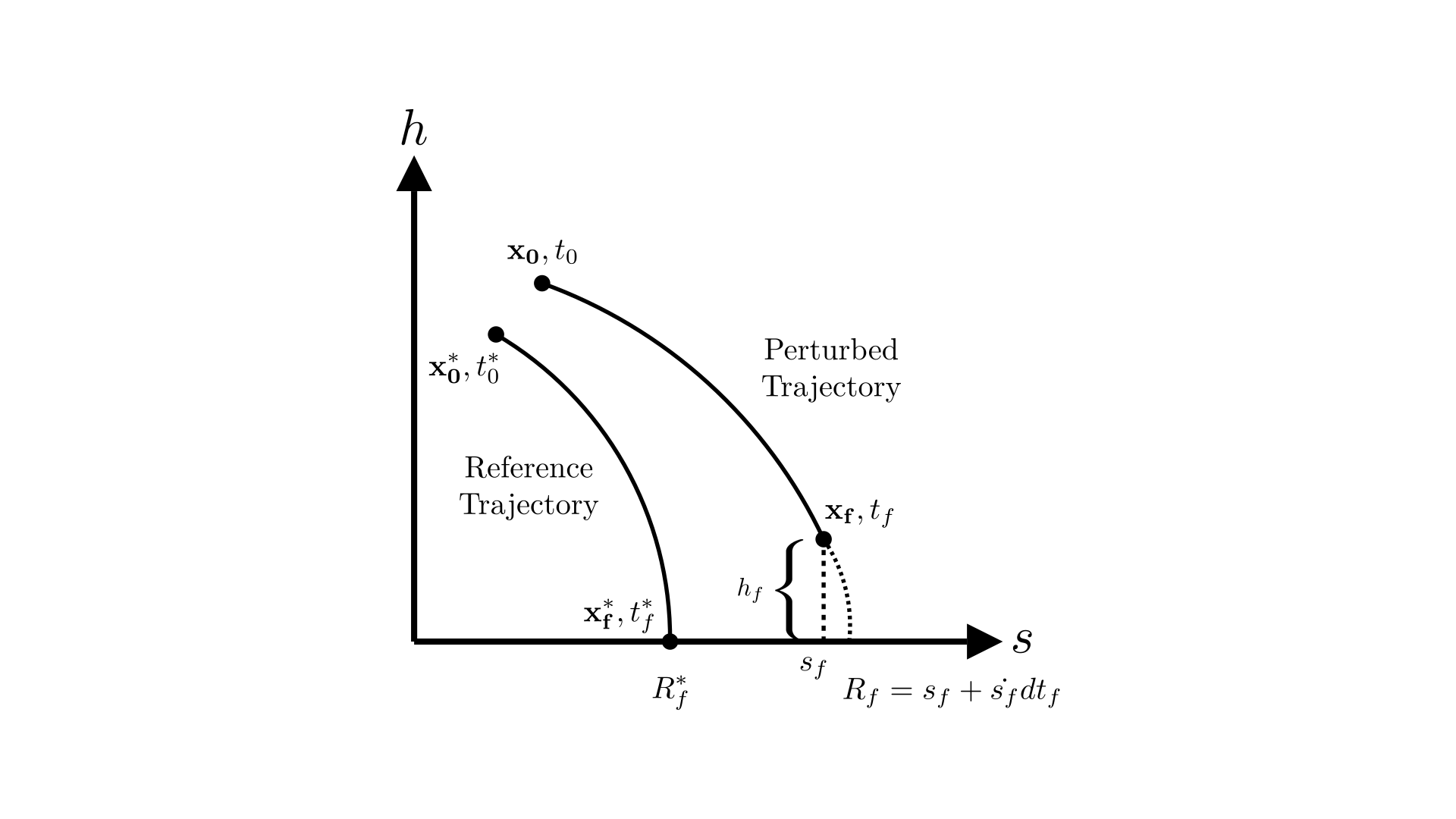
The goal is to find the constant bank angle $u$ that will guide the spacecraft from the perturbed starting state $\mathbf{x_0}$ to the same range as the reference trajectory. Let’s call this function $J$. Any variable with an “f” in the suffix denotes that it is evaluated at the terminal point of the trajectory and the ‘*’ denotes that it is part of the reference trajectory.
From the equations of motion,
Substituting $\eqref{eqn:h_f_expr}$ in $\eqref{eqn:J_1}$,
We want to now find a constant value of $u$ that will keep J constant at $J = R_f = R_f^*$ even with perturbations. We are able to control the trajectory by influencing $u$ and are constrained by physics i.e. equations of motion, $\dot{\mathbf{x}} = \mathbf{f}(\mathbf{x},u,t)$. These constraints can be adjoined to $J$ using co-states $\mathbf{\lambda}^\intercal = \left[\lambda_h\enspace\lambda_s\enspace\lambda_v\enspace\lambda_\gamma\right]$, one for each state. This is very similar to Lagrange multipliers used in function optimization. In this case, each costate is a function that has its own equation of motion which will be derived here.
To find the stationary point of $J$ we apply the variation operator. We also shorten $\mathbf{f}(\mathbf{x},u, t)$ to just $\mathbf{f}$.
Applying the chain rule to the variation operator
Applying Leibniz Rule to the first term of the integral in ${\eqref{eqn:Jprime_1}}$,
Integrating by parts, the fourth term of the integral in ${\eqref{eqn:Jprime_1}}$,
Substituting $\eqref{eqn:Jprime_int_term1}$ and $\eqref{eqn:Jprime_int_term4}$ in ${\eqref{eqn:Jprime_1}}$,
Set $\delta J’ = 0$ to find the stationary point of $J’$. We choose co-states to have the following equations of motion so that they cancel out the third term in $\eqref{eqn:Jprime_2}$:
Now focusing on the first term of $\eqref{eqn:Jprime_2}$,
This gives us the boundary conditions on the costates as follows:
Therefore, assuming the conditions in $\eqref{eqn:costate_eom}$ and $\eqref{eqn:costate_bc_vec}$ hold for the costates, the condition for the stationary point of $J’$ is given by:
Apollo guidance assumes that the bank angle correction, $\delta u$ is constant for the whole trajectory.
Eq. $\eqref{eqn:delu_1}$ is giving us a “correction factor” for the bank angle $u$ that should minimize the range error at the terminal point if applied over the entire trajectory. This needs to be simplified into something that can be computed on-board the flight computers.
Looking at just the numerator of $\eqref{eqn:delu_1}$.
Since we are trying to keep $J$ stationary about the reference trajectory, all of the terms here must be evaluated w.r.t the reference trajectory (denoted by the $^*$). We also change the independent variable to the velocity, $v$ as that is a better value for matching up the current state of the vehicle to the reference state (for computing the $\delta$’s).
Also, the altitude rate $\dot{h}$ and drag acceleration $D/m$ are more accurately estimated by sensors on board the spacecraft than the altitude or flight-path angle.
Assuming exponential atmospheric model with scale height $H$,
Substituting $\eqref{eqn:delgam_to_delhdot}$ and $\eqref{eqn:delh_to_deldm}$ into $\eqref{eqn:delu_numerator}$
For denominator of $\eqref{eqn:delu_1}$, introduce new state $\lambda_u(t)$ such that
One option we have is to compute this integral on board the vehicle in every guidance cycle. However this can be very expensive (especially considering the hardware this was originally designed for). So we differentiate (34) w.r.t $t_0$ and apply Leibniz Rule to get
The boundary condition for $\lambda_u$ can be obtained as :
Apollo Guidance Bank Angle Policy
When we actually implement this guidance algorithm, $t_0$ and $\mathbf{\mathbf{x}_0}$ corresponds to the “current” time and state of the spacecraft. All the $\delta{\mathbf{x}}$ values are therefore computed by comparing the current trajectory to the reference trajectory. For example,
$\delta h(v_0) = h(v_0) - h^{*}(v_0)$
where $h(v_0)$ is the current altitude and $h^*(v_0)$ is the altitude on the reference trajectory corresponding to the current speed.
Putting it all together, $\eqref{eqn:delu_1}$ becomes
The terms containing $*$ can be pre-computed on the ground along with teh reference trajectory. These terms can therefore be substituted by:
Also, it can be found that $\lambda_s$ has a constant value of 1 since $\frac{\partial \mathbf{s}}{\partial s} = 0$ and $\lambda_s(t_f) = 1$.
So the final expression for $\delta u$ becomes:
$\delta u$ is added to the reference bank angle $u$ to obtain the bank angle to be commanded in each guidance cycle.
Some Notes on Implementation
One key bottleneck that I found during implementation was the data-lookup within the reference trajectory data. Right now, the reference trajectory data is stored in a 2D numpy array. In every guidance cycle, we do a lookup within this array to find the data row with the closest value of velocity to the vehicle’s current velocity. This could be made much more efficient with a better data structure.
Conclusion
The Jupyter notebooks implement the algorithm as well as a Monte Carlo simulation system for testing it. I will be updating them to add more notes and details on the implementation to clarify things further.
References
[1] R.D.Braun and R.M. Manning, Mars Exploration Entry, Descent and Landing Challenges
[2] M. Pajola, et. al., Planetary Mapping for Landing Sites Selection: The Mars Case Study
[3] L. Blackmore, Autonomous Precision Landing of Space Rockets, Page 15
[4] C.R. Heidrich, E. Roelke, S.W. Albert and R.D. Braun, Comparative Study Of Lift And Drag Modulation Control Strategies For Aerocapture
[5] Entry System Design Considerations for Mars Landers“ - includes more details about the Apollo Guidance Algorithm on Page 12
[6] P.D. Burkhart et. al., Mars Science Laboratory Entry, Descent, and Landing System Overview
[7] G.F. Mendeck, Mars Science Laboratory Entry Guidance
[8] D.G. Ives, D.K. Geller and G.L. Carman, Apollo-derived Mars precision lander guidance
[9] G.F. Mendeck and G.L. Carman, Guidance Design for Mars Smart Landers Using the Entry Terminal Point Controller